
Predicting the Unpredictable
Replacing Estimates with Data-Driven Forecasting,
One thing I and my teams have struggled with time and time again is how to predict how long projects will take. One common strategy is to identify a Minimum Viable Product (MVP) - the smallest set of features that will provide value, and deliver that as soon as possible. Once the MVP is completed, features can be added and delivered in priority order. This keeps timelines small and predictable.
However, there are often situations where the MVP is still big. There are various reasons for this: a start-up may not want to squander their big marketing push for something that has no substance, or a larger company may have a legacy system to replace and the new one has to maintain feature parity before it can be used. In these cases a larger effort is required before the first release, but the question remains... "When will it be done?"
I've been a part of many attempts at answering this question for large projects using estimation techniques such as story points, t-shirt sizing, and measuring "velocity", but it always seems to take longer. Usually it's acknowledged that we don't know what unforseen issues will creep up, but they always do so we include some type of buffer for that. And again, it always seems to just take longer.
Hofstadter's Law: It always takes longer than you expect, even when you take into account Hofstadter's Law.
These experiences led me to find "When Will It Be Done?" by Daniel S. Vacanti. In it he provides a more data-driven, probabilistic approach to answering the question.
The Flaw of Averages
One of the key takeaways from Vacanti's book is the distinction between estimating and forecasting. Estimating implies a level of certainty that's often unrealistic, while forecasting acknowledges the uncertainty inherent in predicting the future.
Here's an example, let's say you're trying to predict your initial hand value in blackjack. In the following table I've enumerated all possible hands along with their value and the probability of getting one of the hands with that value. In the column on the right is the percentile, or the chance that you'll get that value or less.
| Possible Hands | Value | Probability | Percentile |
|---|---|---|---|
| 22 | 4 | 0.7% | 0.7% |
| 23, 32 | 5 | 1.4% | 2.1% |
| 24, 42, 33 | 6 | 2.1% | 4.2% |
| 25, 52, 34, 43 | 7 | 2.8% | 6.9% |
| 26, 62, 35, 53, 44 | 8 | 3.5% | 10.4% |
| 27, 72, 36, 63, 45, 54 | 9 | 4.2% | 14.6% |
| 28, 82, 37, 73, 46, 64, 55 | 10 | 4.9% | 19.4% |
| 29, 92, 38, 83, 47, 74, 56, 65 | 11 | 5.6% | 25.0% |
| AA, 2J, J2, 2Q, Q2, 2K, K2, 39, 93, 48, 84, 57, 75, 66 | 12 | 9.7% | 34.7% |
| A2, 2A, 3J, J3, 3Q, Q3, 3K, K3, 49, 94, 58, 85, 67, 76 | 13 | 9.7% | 44.4% |
| A3, 3A, 4J, J4, 4Q, Q4, 4K, K4, 59, 95, 68, 86, 77 | 14 | 9.0% | 53.5% |
| A4, 4A, 5J, J5, 5Q, Q5, 5K, K5, 69, 96, 78, 87 | 15 | 8.3% | 61.8% |
| A5, 5A, 6J, J6, 6Q, Q6, 6K, K6, 79, 97, 88 | 16 | 7.6% | 69.4% |
| A6, 6A, 7J, J7, 7Q, Q7, 7K, K7, 89, 98 | 17 | 6.9% | 76.4% |
| A7, 7A, 8J, J8, 8Q, Q8, 8K, K8, 99 | 18 | 6.3% | 82.6% |
| A8, 8A, 9J, J9, 9Q, Q9, 9K, K9 | 19 | 5.6% | 88.2% |
| A9, 9A, JJ, JQ, QJ, JK, KJ, QQ, QK, KQ, KK | 20 | 7.6% | 95.8% |
| AJ, JA, AQ, QA, AK, KA | 21 | 7.7% | 100% |
If you were to pick one of the two outcomes tied for most likely (12 or 13), you would only be right 9.7% of the time. Even if you were able to pick both of the most likely outcomes, you would only be right 19.4% of the time. You'd be better off predicting "11 or less" - you'd be right 25% of the time. Widen the range even more and you can be more certain... "19 or less" is right 88.2% of the time. Of course, you can be right every time if you say "21 or less" but then the range is so wide you can't really do anything useful with that information.
Principles of Forecasting
To improve our forecasting skills, we need to adopt a few key principles:
-
Think probabilistically: Instead of predicting a single outcome, we should consider a range of possible outcomes and their associated probabilities.
-
Near-term forecasts are more accurate: The closer we are to the completion date, the more accurate our forecasts tend to be.
-
Re-forecast when new information is received: As new data becomes available, we should update our forecasts to reflect the changing circumstances.
Single Item Forecasts
When forecasting the completion date of a single item, we can use a technique called cycle time analysis. Cycle time is the amount of time it takes to complete one unit of work, and it can be used to forecast future items. By plotting cycle time against the completion date, we can identify outliers and potential system stability improvements.
Let's say we've got some data from our work tracking tool that lists each completed item along with the date it was started and the date it was done. Here we have 10 completed items.
const completedItems = [
{ startedDate: new Date(2024, 11, 26), doneDate: new Date(2025, 0, 1) },
{ startedDate: new Date(2024, 11, 25), doneDate: new Date(2025, 0, 2) },
{ startedDate: new Date(2024, 11, 12), doneDate: new Date(2025, 0, 3) },
{ startedDate: new Date(2024, 0, 6), doneDate: new Date(2025, 0, 6) },
{ startedDate: new Date(2024, 11, 31), doneDate: new Date(2025, 0, 6) },
{ startedDate: new Date(2024, 11, 31), doneDate: new Date(2025, 0, 8) },
{ startedDate: new Date(2025, 0, 6), doneDate: new Date(2025, 0, 9) },
{ startedDate: new Date(2025, 0, 13), doneDate: new Date(2025, 0, 14) },
{ startedDate: new Date(2025, 0, 13), doneDate: new Date(2025, 0, 14) },
{ startedDate: new Date(2025, 0, 9), doneDate: new Date(2025, 0, 15) },
];We can also calculate the earliest and latest done dates.
const earliestDate = new Date(Math.min(...completedItems.map((c) => c.doneDate)));
const latestDate = new Date(Math.max(...completedItems.map((c) => c.doneDate)));Cycle time can be calculated by subtracting the completion date from the date that the work was started. Here we're dividing so that we're working with days and then adding one because if a work item starts and ends on the same day we want it to count as a cycle time of one day.
const getCycleTime = (item) => {
return (item.doneDate - item.startedDate) / (1000 * 3600 * 24) + 1;
};Now we'll make use of the quantile function in D3 to find the cycle time that corresponds to the 85th percentile of items:
const eightyFifthCycle = d3.quantile(completedItems, 0.85, getCycleTime);Finally, we'll use Apache ECharts to make a chart of the cycle times and the 85th percentile line.
cycleTimeChart = echarts.init(document.querySelector("#cycleTime"));
cycleTimeChart.setOption({
title: {
text: "Cycle Time",
},
xAxis: {
axisLabel: { formatter: "{M}/{d}" },
name: "Completion Date",
nameGap: 35,
nameLocation: "middle",
type: "time",
},
yAxis: {
name: "Elapsed Days",
nameGap: 35,
nameLocation: "middle",
nameRotate: 90,
},
series: [
{
type: "scatter",
animationDuration: 500,
data: completedItems.map((c) => [c.doneDate, getCycleTime(c)]),
tooltip: {
valueFormatter: (value) => value + (value === 1 ? " day" : " days"),
},
},
{
type: "line",
animationDuration: 500,
symbol: "none",
endLabel: {
show: true,
formatter: "85th percentile\n{@[1]} days or less",
fontSize: 16,
offset: [-115, -20],
},
data: [
[earliestDate, eightyFifthCycle],
[latestDate, eightyFifthCycle],
],
},
],
tooltip: {
trigger: "item",
},
});
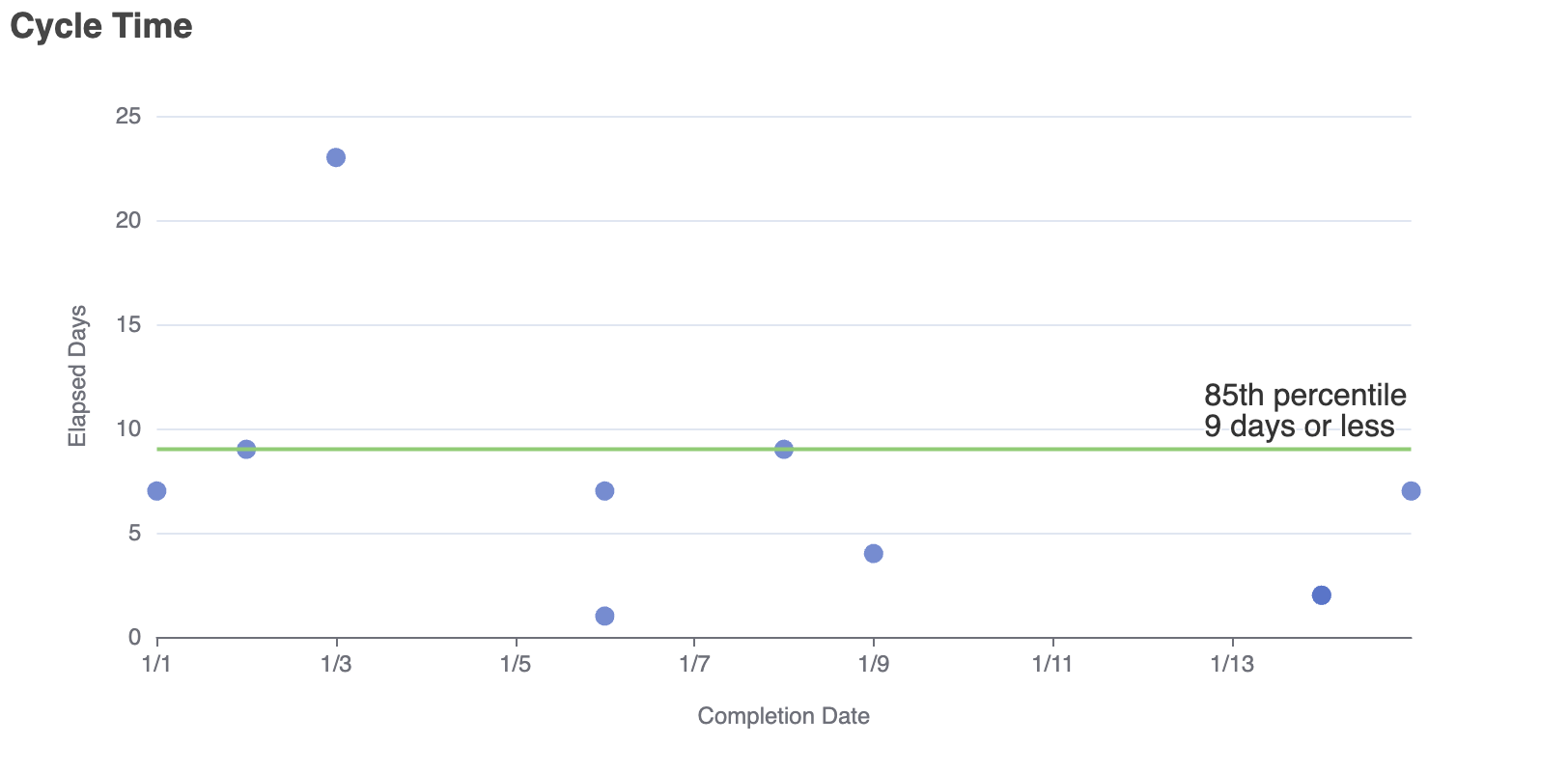
Looking at this chart we can gather a few things. One, we can be fairly certain that any new piece of work we want to get done will take 9 days or less (of course we can always choose a different percentile than 85% if we want either more certainty or a smaller time range). And two, there's one work item that took significantly more than that: 23 days. It's probably worth investigating - it may have legitimately taken that long, but sometimes you'll find that it was waiting on some dependency which could lead to an opportunity to improve the process.
In fact, it turns out that the smaller you can make your work items the smaller your cycle time will be - which in turn increases the accuracy of your forecasts.
Multi-Item Forecasts
In fact, it turns out that the smaller you can make your work items the smaller your cycle time will be - which in turn increases the accuracy of your forecasts.
First, let's define throughput to be the number of items completed on a specific day. We'll use the throughput of the date range of our existing data to assign a random throughput to days in the future until there are no items left to complete. We can then run that simulation any number of times and plot the results. For this example we'll run it 1,000 times.
We still have the earliest and latest date, so we can make a range of dates between them like this:
const makeDateRange = (firstDate, lastDate) => {
let result = {};
let d = new Date(firstDate);
while (d <= lastDate) {
result[d] = 0;
d.setDate(d.getDate() + 1);
}
return result;
};
const doneDateCounts = makeDateRange(earliestDate, latestDate);The dates are keys in an object and we can set the values to the throughput for that day by counting how many items were completed on that day:
for (let item of completedItems) {
doneDateCounts[item.doneDate]++;
}Now we're ready to run the simulation...
let simulatedDates = {};
const iterations = 1000;
const totalItemCount = 100;
for (let i = 0; i < iterations; i++) {
// start each iteration by calculating the number of items left to complete
let numItemsLeft = totalItemCount - completedItems.length;
let simulationDay = new Date(latestDate);
// loop through future dates until there is no more work to do
while (numItemsLeft > 0) {
// the first day of the simulation will be the day after the latest date of the completed work
simulationDay.setDate(simulationDay.getDate() + 1);
// pick a random day and get the throughput
const randomItemIndex = Math.floor(Math.random() * completedItems.length);
const randomDay = completedItems[randomItemIndex].doneDate;
const throughput = doneDateCounts[randomDay];
// and subtract the throughput for that day from the work items left
numItemsLeft -= throughput;
}
// once the work is done for this iteration, increment the count for the number of times the simulation ended on that day
simulatedDates[simulationDay] = (simulatedDates[simulationDay] || 0) + 1;
}Now we have an object with keys representing dates and values representing the number of simulation iterations that ended on that date. Let's transform it into an array so that we can sort by date for calculating the 85th percentile and so we can chart it.
const histogramData = Object.entries(simulatedDates)
.map(([dateString, occurrences]) => [new Date(dateString), occurrences])
.toSorted((a, b) => a[0] - b[0]);To calculate the 85th percentile, we'll count occurrences until we get 85% of the total.
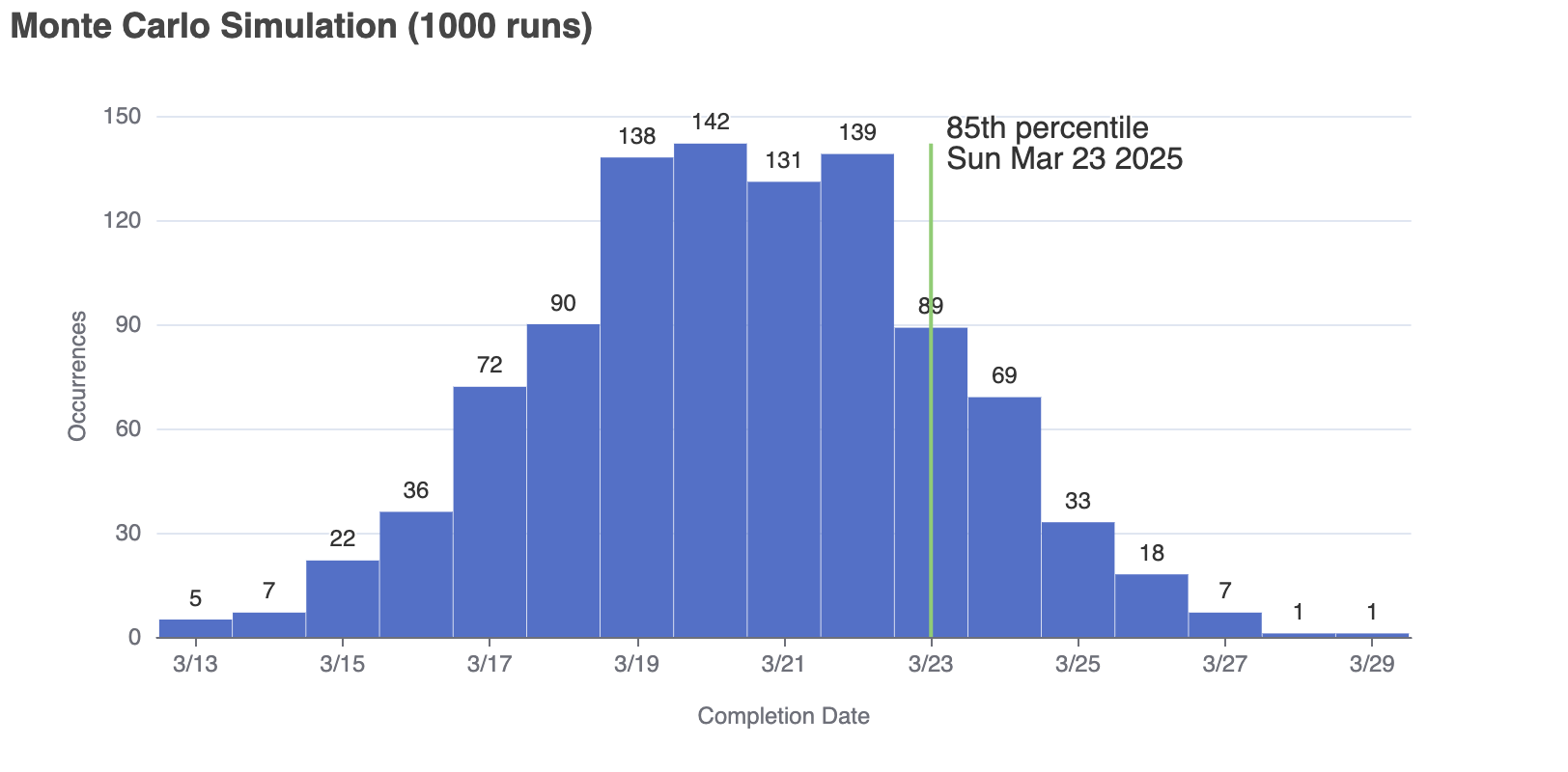
let counted = 0;
let eightyFifthCompletion;
for (let i = 0; counted <= iterations * 0.85; i++) {
eightyFifthCompletion = histogramData[i][0];
counted += histogramData[i][1];
}Now we can visualize the results:
monteCarloChart = echarts.init(document.querySelector("#monteCarlo"));
monteCarloChart.setOption({
title: {
text: `Monte Carlo Simulation (${iterations} runs)`,
},
xAxis: {
axisLabel: { formatter: "{M}/{d}" },
name: "Completion Date",
nameGap: 35,
nameLocation: "middle",
type: "time",
},
yAxis: {
name: "Occurrences",
nameGap: 35,
nameLocation: "middle",
nameRotate: 90,
},
series: [
{
type: "bar",
animationDuration: 500,
barWidth: "99%",
label: {
show: true,
position: "top",
},
data: histogramData,
tooltip: {
formatter: (params) => params["value"][0].toDateString(),
},
},
{
type: "line",
animationDuration: 500,
symbol: "none",
endLabel: {
show: true,
formatter: (params) => "85th percentile\n" + params["value"][0].toDateString(),
fontSize: 16,
},
data: [
[eightyFifthCompletion, 0],
[eightyFifthCompletion, Math.max(...histogramData.map((e) => e[1]))],
],
},
],
tooltip: {
trigger: "item",
},
});
Re-Forecasting
At this point we're thinking probabilistically instead of deterministically, but that's one out of the three forecasting principles. The second is that short term forecasts are more accurate than long term forecasts, and the third is that we should re-forecast when there is new information. The third essentially addresses the second because when you re-forecast, you're replacing an older forecast with a newer likely shorter one. Over time, your forecasts will get more and more accurate because the amount of known information increases and the amount of unknown information decreases. The more often you re-forecast, the quicker you can make decisions based on the new information.
In the beginning of the book the author uses the example of forecasting hurricane paths done by the National Hurricane Center. Their policy is to produce updated forecasts every 8 hours at a minimum while tracking an active storm. Every time they re-forecast, the previous one is invalidated because it is based on outdated information. This way if the storm changes direction unexpectedly the affected areas can take action as soon as possible.
If your team has a regular project status cadence, you might consider re-forecasting at that time. Or even better, you could automate the forecast and publish an update every time a work item is completed, deleted, or added.
Final Thoughts
One thing to watch out for is that it is a bit of an art form to choose your input data for these forecasts. In your organization, for example, it may be common for things to get hectic during certain times of the year. It might be worth choosing input data that lines up with the time of the year that you are forecasting. Another variable might be team composition - if a team loses or gains a new member, it can change the dynamic and it might be worth using only data since the change.
The book also covers methods for improving the accuracy of forecasts by measuring and adjusting the stability of your workstream system. This can be incorporated into any continuous improvement practice.
I hope this has inspired you to use some of these methods to reduce the time you spend estimating up front (and eventually being proven wrong) and leverage the data you have and will continue to get to make forecasts that can inform decision makers on a regular basis.
Comments (0)
Leave a Comment
No comments yet. Be the first to share your thoughts!